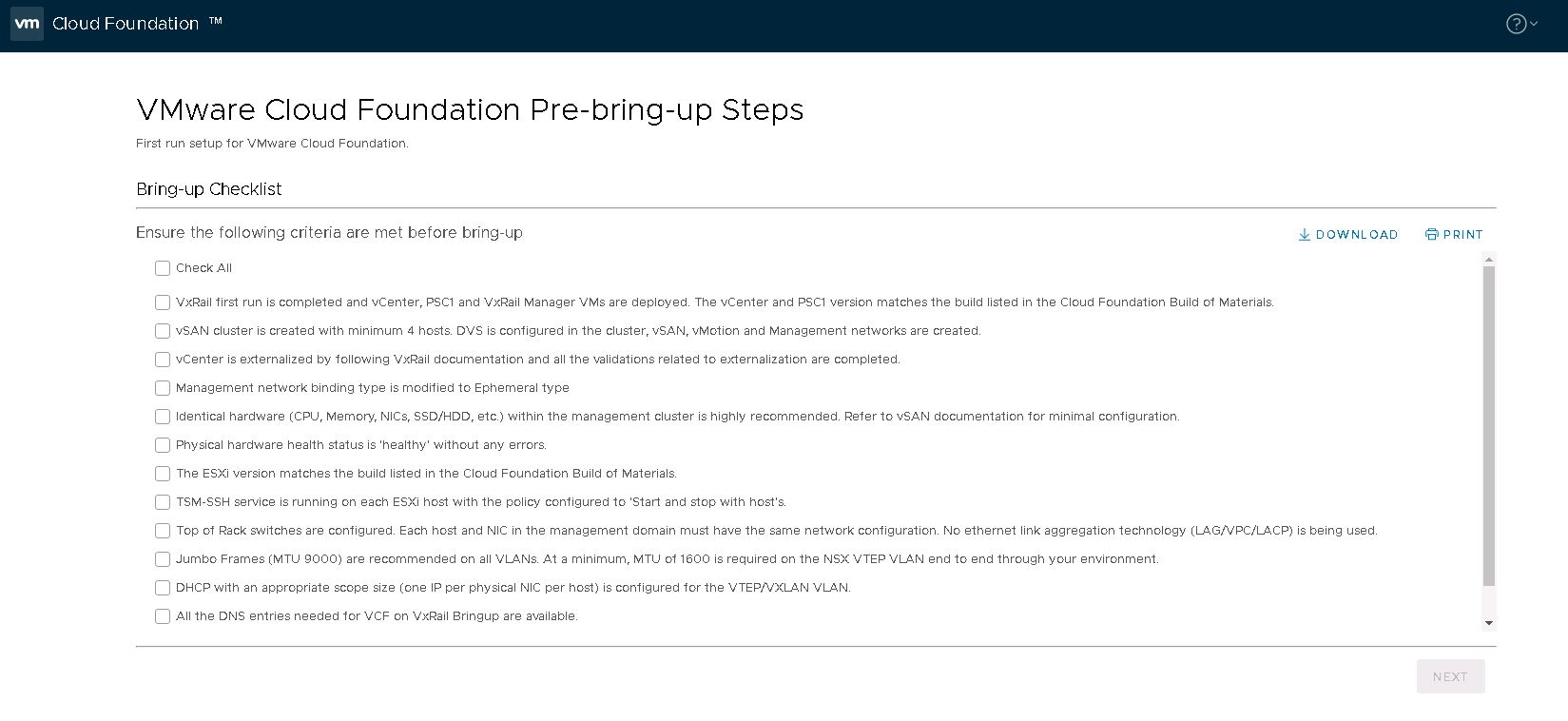
Introduction
Introduction
I had a conversation with a colleague recently about VMware HCX, specifically around network requirements and the minimum link specifications we’d need to have between two sites so that the basic functionality would work as intended.
I threw out a figure that I knew was well in excess of what would be required for HCX (and all the other services that need to be run over the link) but it got me thinking; How bad could the link get before even basic HCX services would just stop working?
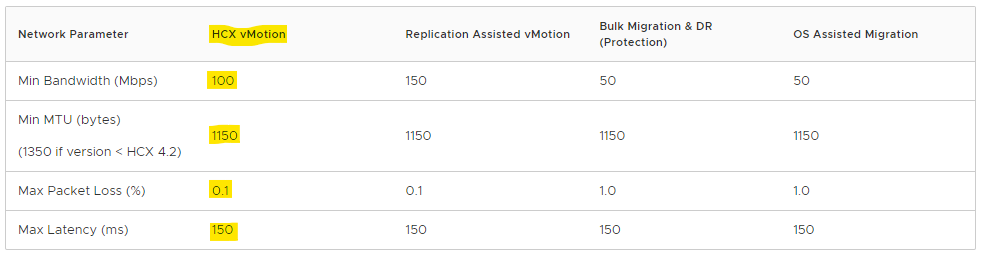
I was a little surprised to read the figures in the below table from the VMware docs site and I’ve highlighted the numbers I’m interested in for HCX vMotion. The bandwidth figure listed is quite a bit lower than I thought would be recommended. I’m even more surprised by the latency figure, quite a lot higher than I imagined HCX would endure.
With the above in mind, lets see what it takes to break HCX.
The Lab
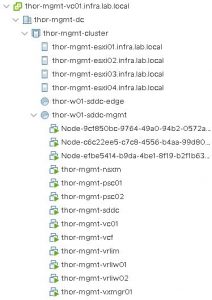
But first, this. My test environment consists of two VxRail clusters running on 13G nodes with version 7.x code. Networking is 10G everywhere and between the two sites I’ve got a Netropy 10G link emulator to provide all the link state related horror later on. As HCX encapsulates traffic within a tunnel between sites, the traffic inspection options in the Netropy are going to be less useful to me to be able to pull specific traffic off a link. Instead, I’ve done my best to isolate all HCX traffic to a single 10G NIC on each cluster. In all migration tests, I’m using clones of an 80GB Windows 2012 VM.
I should also point out that this is by no means a benchmark, nor should it be interpreted as such. I was merely curious at what point HCX would stop working in my existing lab environment. The test environment hasn’t been endlessly tweaked for maximum vMotion performance. It’s pretty much a straight out of the box VxRail build.
We already know that a 10G link with very little latency is going to work just fine and yes I did run a migration to test that.
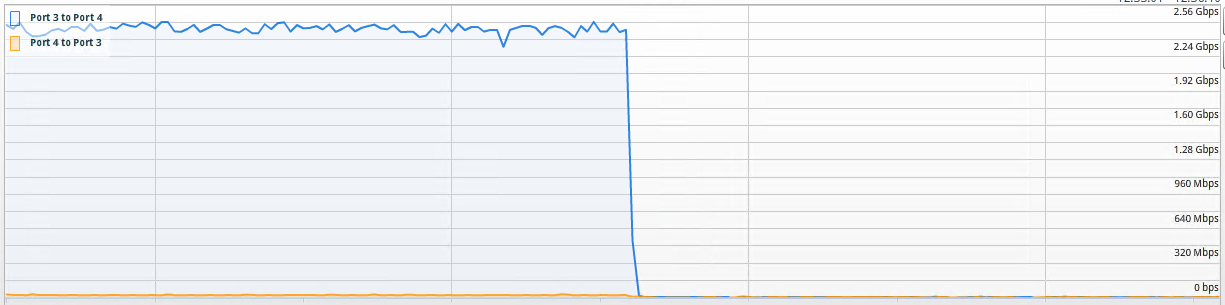
The transfer speed axis is a little bit of an eye chart, but it’s within 2.3 to 2.6Gbps. The transfer did initially spike to 6.8Gbps, but it settled to it’s final figure pretty quickly.
Testing VMware minimums
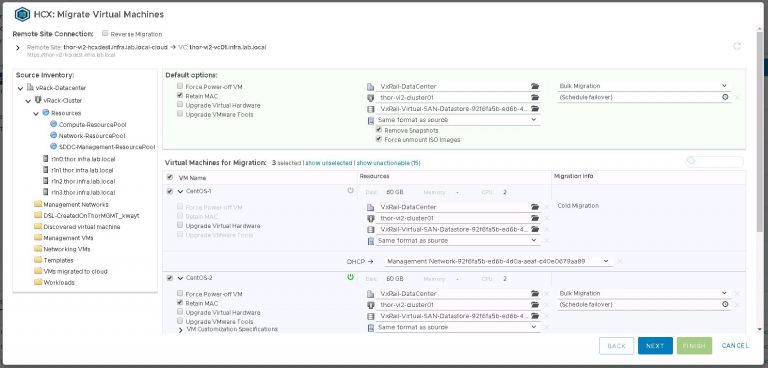
With that out of the way, lets get straight to the VMware quoted minimums. I modified the link characteristics of the Netropy to 100Mbps with a fixed 150ms of latency. In the screenshot below, 75ms is applied in each direction for a total of 150ms for the round trip.
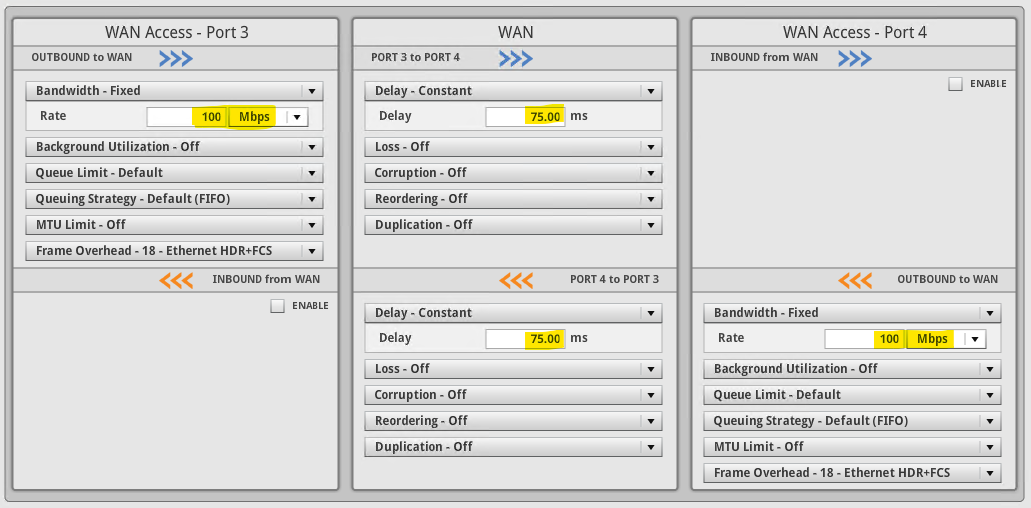
At this new setting the response time of the HCX dialogs within vSphere client are somewhat slower, taking marginally longer to refresh and gather cluster information from the remote site. Once all the information has been gathered though, the process of selecting migration options is just as quick as with a faster/lower latency link.
Once the migration kicked off, it did max out the available line-rate initially, only dropping to about 35Mbit after 60-70% of the migration had completed.
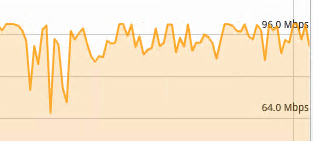
To migrate the entire 80GB VM took a little over 4 hours. While that time is far from ideal in a production environment, it becomes more acceptable depending on the frequency and quantity of migrations. Keep in mind also that it’s not exactly a tiny VM that I’m pushing around here. In a small production environment or one where mobility is restricted to disaster recovery scenarios (where the VMs would be kept in sync between sites according to RPO/RTO), it becomes almost workable.
Pushing the limits
But it’s still not broken, so I’m not done. What if instead of moving your VMs to the other side of the country, you’re moving them to the other side of the world. Lets keep the same 100Mbit link but ramp the latency to 300ms.
The most charitable thing I can say about the beginning of the process was that the migration dialog did eventually open. I measured the time it took to do that in one cup of coffee made & consumed, and several minor household tasks completed. Lets say 15-20 minutes. Like the previous attempt, once the dialog opened and information was pulled from the remote site, selecting all required migration options was snappy and responsive.
Unsurprisingly, further trouble is just around the corner and once I kicked off that migration, everything ground to a halt once again. The length of time that the base sync performed at the beginning of the migration took to complete was a sign that I probably shouldn’t wait around for live stats on this one. Before shutting down for the evening, I did see peak speeds of between 50 and 60Mbps reported by the Netropy device.
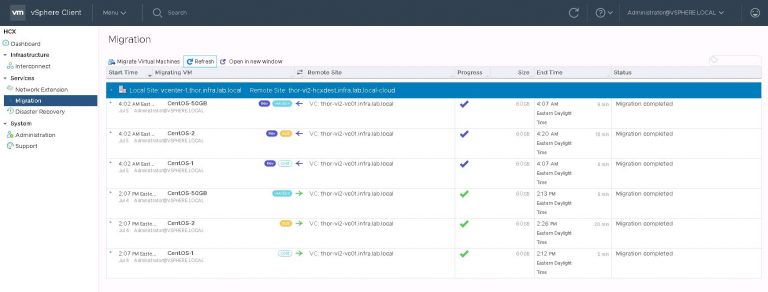
Today is tomorrow and the results are in.
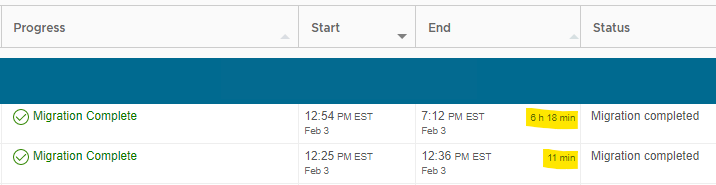
If the text is small and hard to read, let me help. It’s 11 minutes (for the 10Gbit link) versus 6 hours and 18 minutes. Needless to say, if you’re moving VMs to and from a distant site, be that another private site or a VMware Cloud on AWS region and all you’ve got is a 100Mbit link, you’re probably going to reserve the use of vMotion for special occasions. In this scenario, bulk migration with scheduled switchover might be your best friend. Or at least a way to preserve your sanity.
Pushing Bandwidth
You know what I’m going to say next. Even taking the above dismal results into account, HCX still works on a 100Mbit link with 300ms latency. It’s still not broken. The territory I’m entering now is well within the realm of testing with a link that is of zero use for any kind of traffic. I’m more concerned with finding out what happens with low bandwidth right now, so I’ll drop the link speed significantly to 20Mbit and return the latency to the VMware recommended minimum of 150ms. I fully expect the migration to succeed, even if it does take a day to do so. Onward, and downward!
But not downward far enough it seems, the migration still completed successfully at 20Mbit/150ms. It did take over 16 hours mind you, but the end result is what matters here.
![]()
From here, I’m conflicted about taking the bandwidth any lower. If you’re thinking about multi-site private cloud or hybrid private/public deployment and you can’t get at least a 20Mbit link between your sites, it’s almost certainly time to re-evaluate the deployment plan. So lets say the minimum bandwidth test result is a resounding pass. Even if all that’s available is VMware’s minimum recommended of 100Mbit, it’s going to be sufficient to migrate VMs between sites with relative ease.
Pushing Latency
So instead, I’m going to bring the bandwidth available back to a very healthy 500Mbit and focus instead on two things; Latency and packet loss. First up is latency and as I’ve already shown that even 300ms (double the VMware quoted minimum) still results in a successful migration, I’m going to double the double to 600ms.
Despite the huge jump in bandwidth since the last run, the equally huge jump in latency is firmly putting the link back into the almost unusable territory. With the migration running, the charts are showing exactly that.
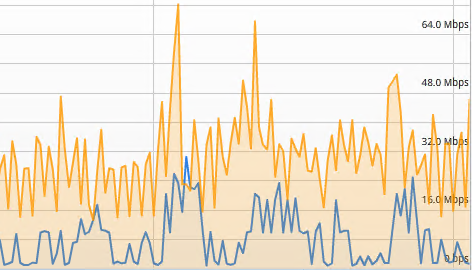
At peak, less than a fifth of the total bandwidth available is being used and the average use is less than half the peak. Nothing out of the ordinary for a link with such high constant latency. Accordingly, migration time is huge at just over 12 hours.
Dropping Packets
My last attempt to prevent HCX from doing it’s job is to introduce packet loss to the link. The VMware table at the top of the post specifies a maximum loss of 0.1%. This feels very like another worst case scenario kind of test. A high level of packet loss on any link isn’t something that would be tolerated. For this test, I’m going to remove the latency from the link, but maintain the 500Mbit bandwidth. I’m introducing 5% packet loss.
The results are nothing shocking. For anyone not familiar, packet loss with TCP traffic on a link will cause packet transmission issues and re-transmissions will happen, effectively slowing down any data transfers.
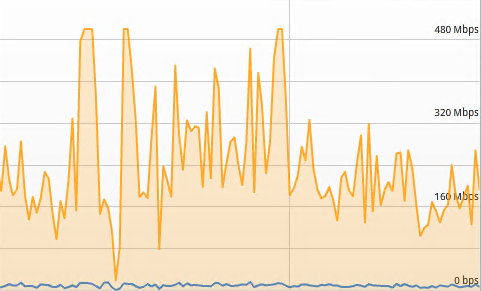
With 5% packet loss set, average bandwidth is a fraction of the potential 500Mbit link speed.
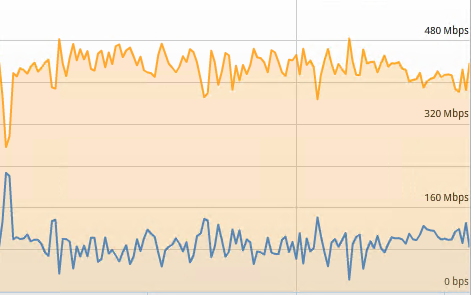
With no packet loss, practically the entire 500Mbit link is used.
As packet loss increases, the above downward trend would continue until the link is unusable. As with the other tests above, HCX appears no more sensitive to poor link quality than any other network traffic would be.
Conclusion
It has become apparent that HCX will perform adequately on any link that is of relatively decent quality. It continues to function with acceptable performance well below the recommended figures that VMware quote in documentation. As I have stated in the tests above, I would expect that if the link between sites functions then HCX will also function.
To put a little more of a ‘real world’ slant on this, I performed a simple latency test to several AWS regions in which it’s possible to run VMware Cloud services and therefore act as a hybrid cloud into which VMs can be migrated using HCX. 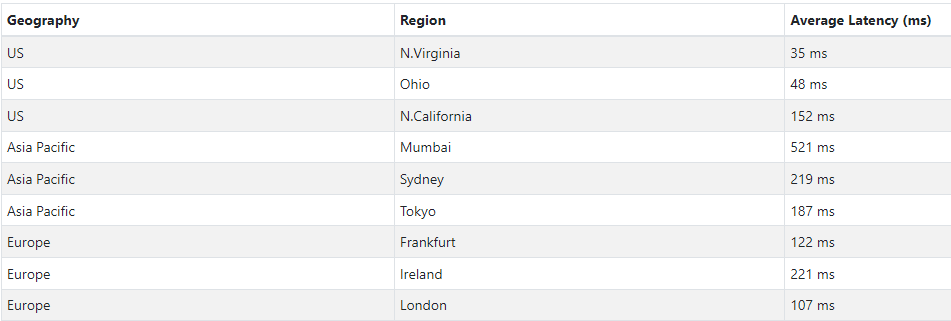
My test environment is located in eastern US, so latency to US regions is lowest. Keeping in mind that I tested all the way to 600ms of latency and had successful, albeit slow transfers, it makes any of the available regions above seem viable.
It is obviously not realistic to expect HCX to be able to perform any magic tricks and work well (or at all) over a link so poor that any other network traffic would have issues traversing. I am pleased that my proposition at the beginning of this post was incorrect. I assumed there would be a point at which a built-in timeout or process error would take the whole thing down and HCX would beg for a faster and more stable link. I also assumed that when that happened, I’d still be able to show that inter-site connectivity was up and somewhat functional outside of HCX.
A somewhat anticlimactic conclusion perhaps, but one that’ll be of great use for my next HCX conversation. At least now I know that when a colleague asks what kind of link they need for HCX, I can confidently answer “anything that works”.




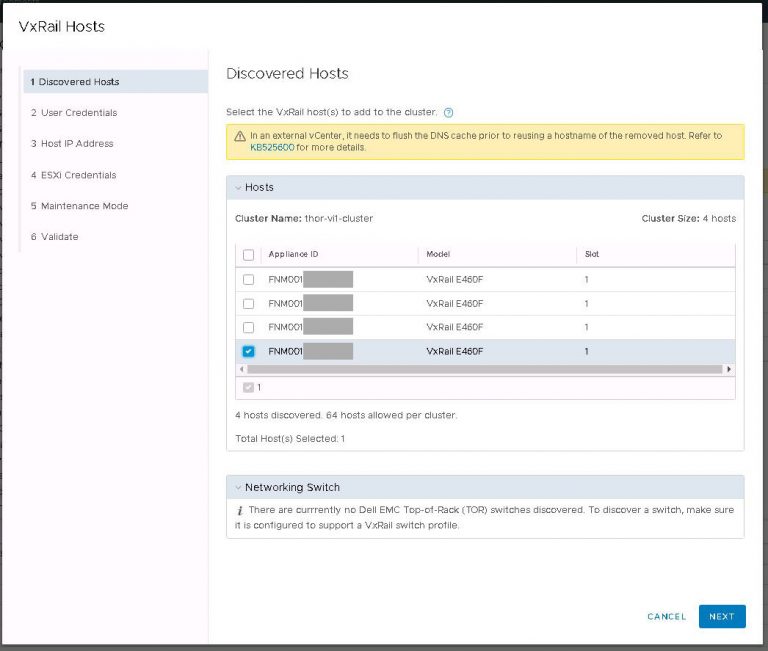
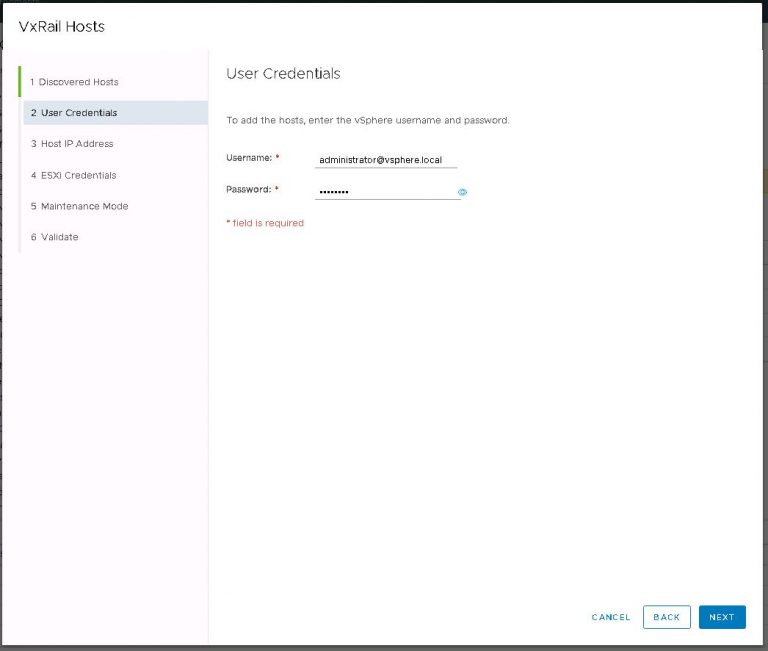
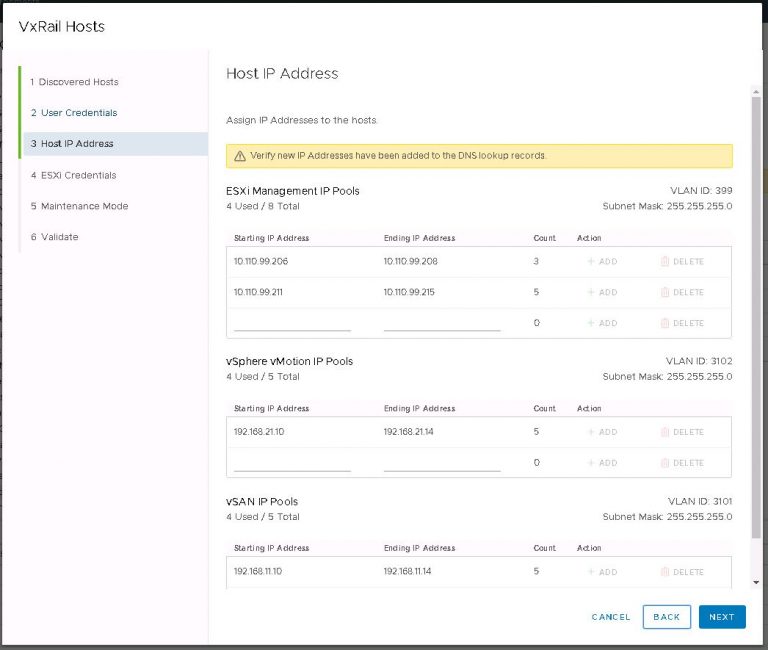
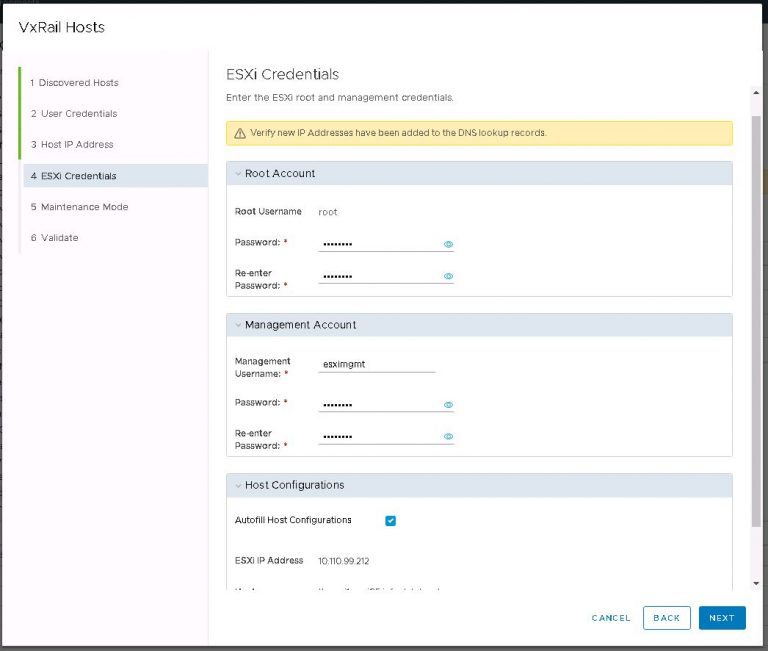
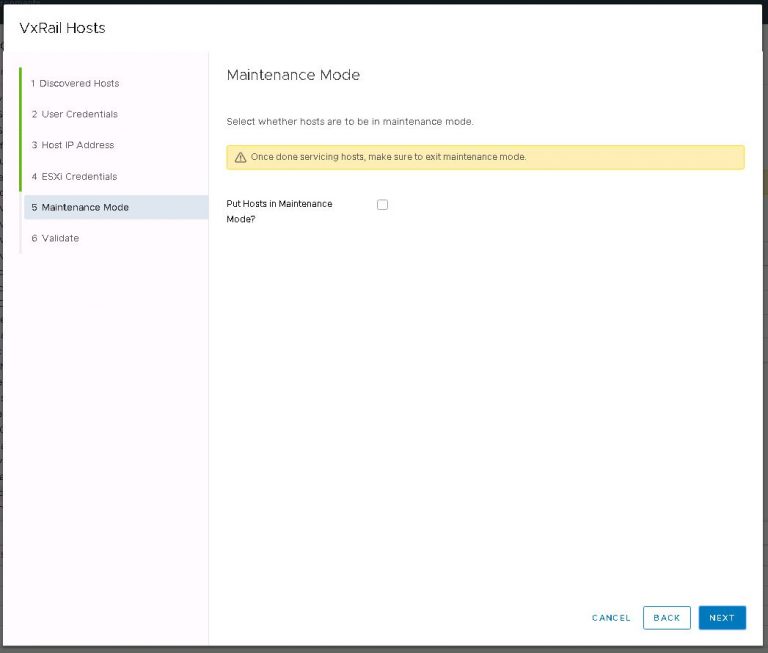
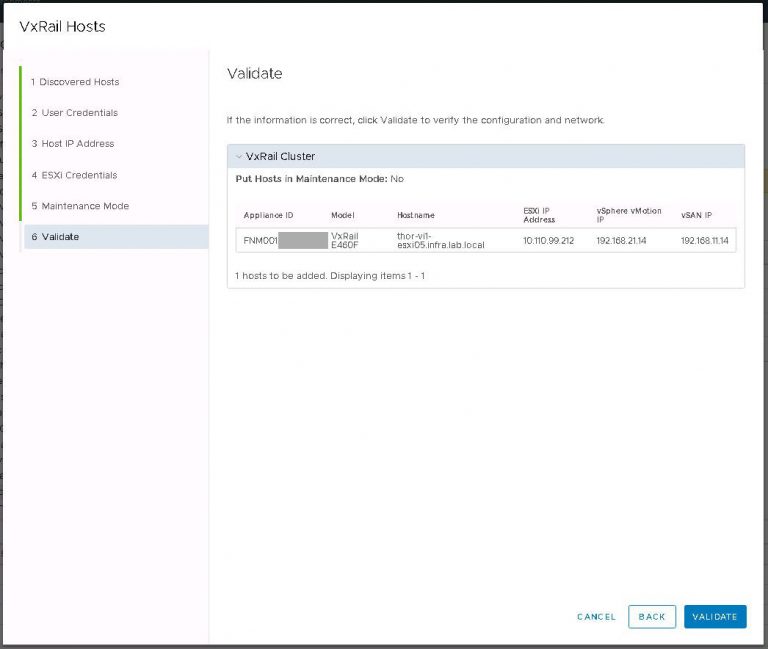
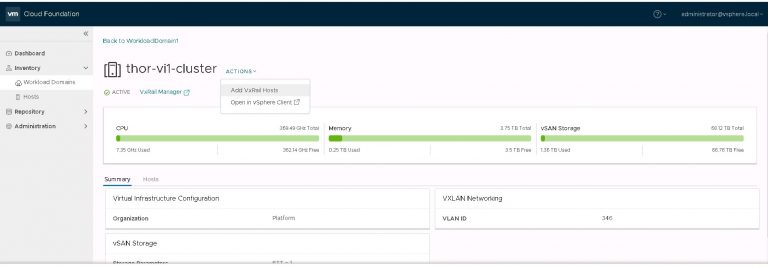
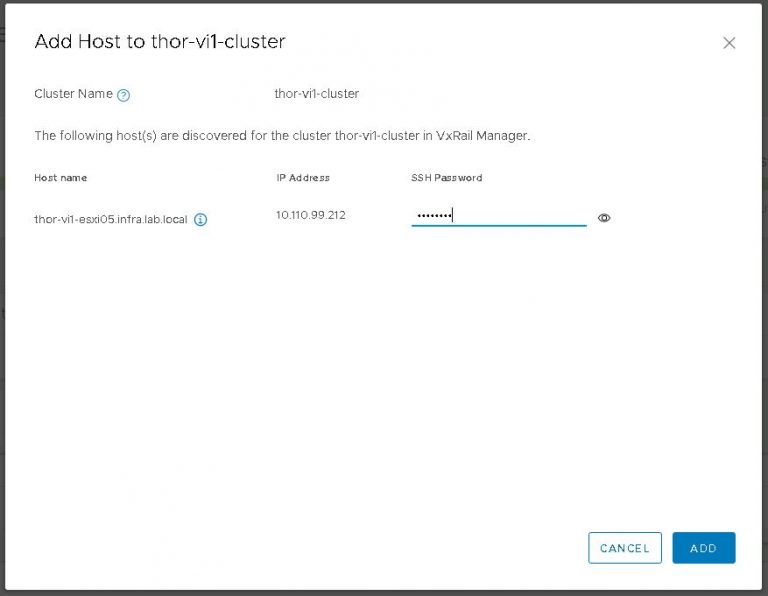


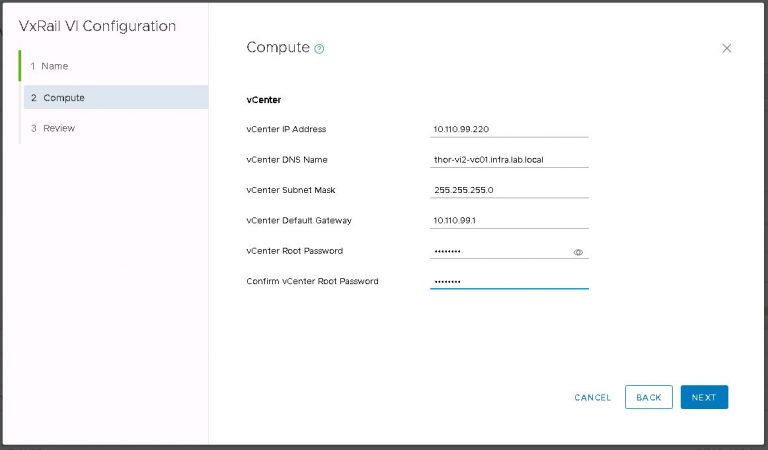
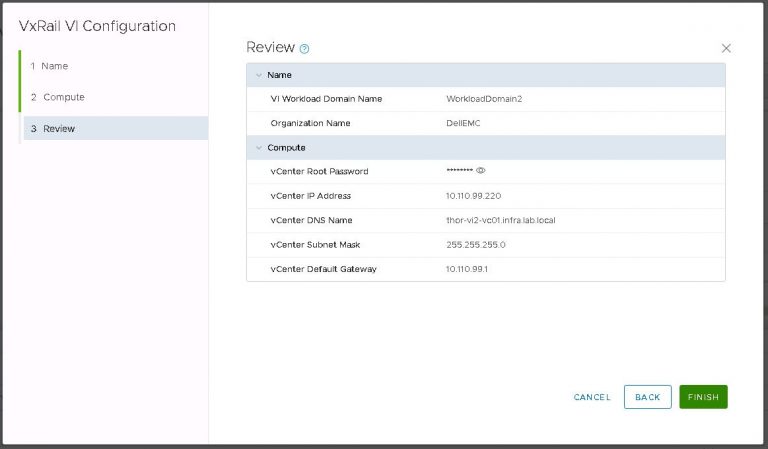

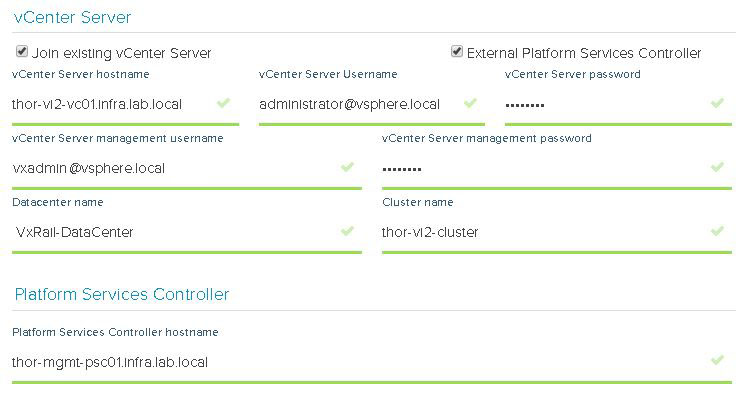

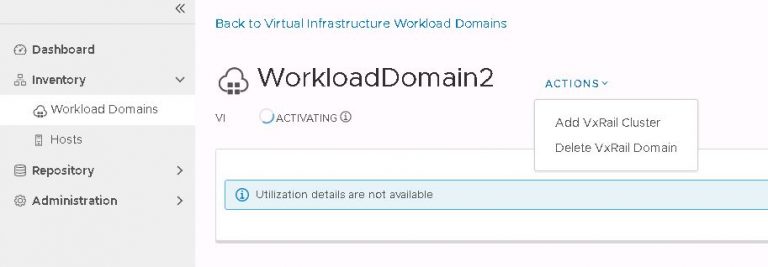
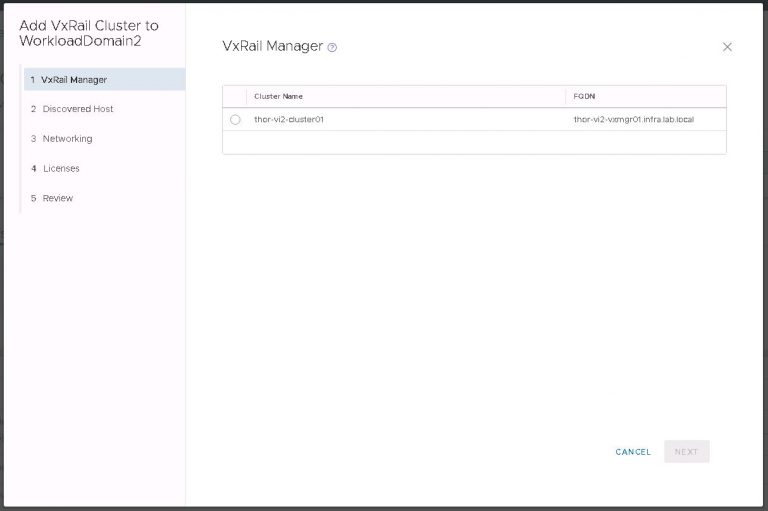
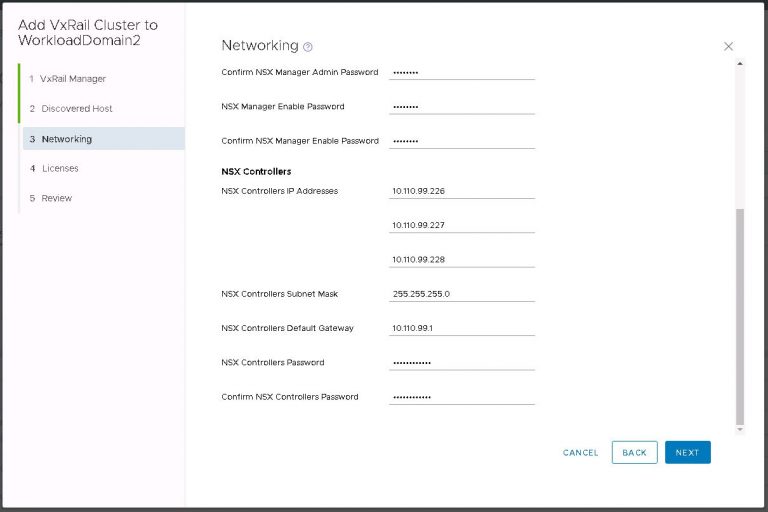
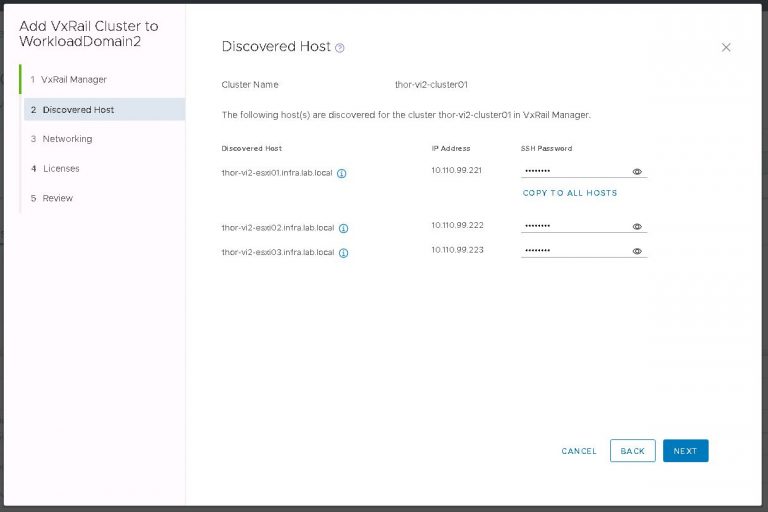 Next up is NSX settings. Very self-explanatory, nothing out of the ordinary here. I entered my VXLAN VLAN ID and some IP settings for both the NSX manager and controller cluster.
Next up is NSX settings. Very self-explanatory, nothing out of the ordinary here. I entered my VXLAN VLAN ID and some IP settings for both the NSX manager and controller cluster.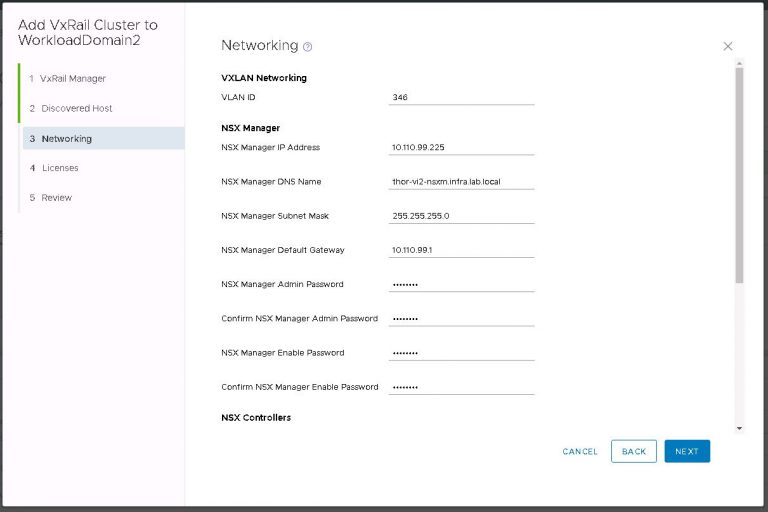
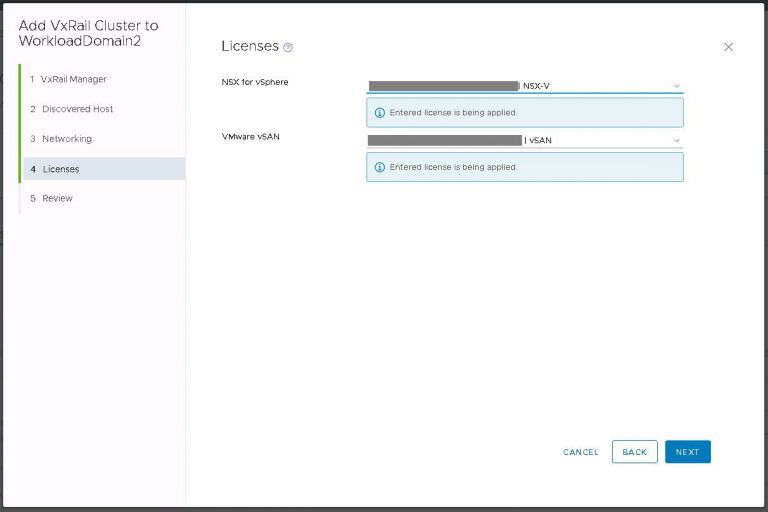
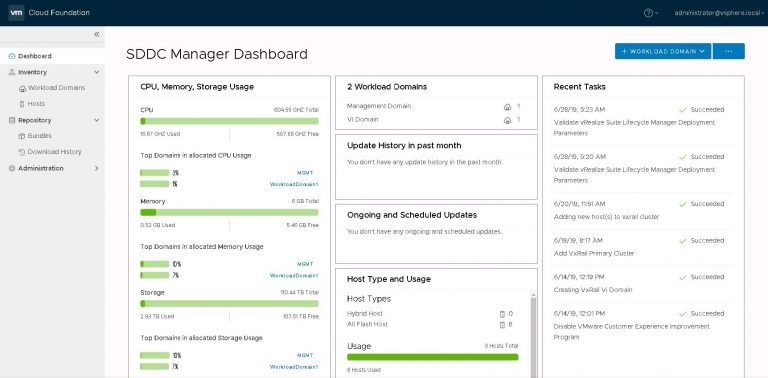
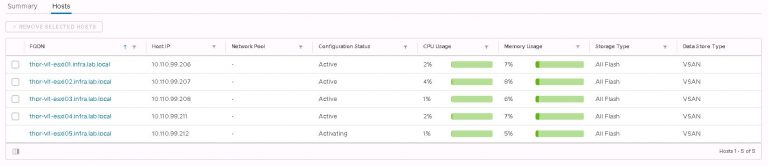
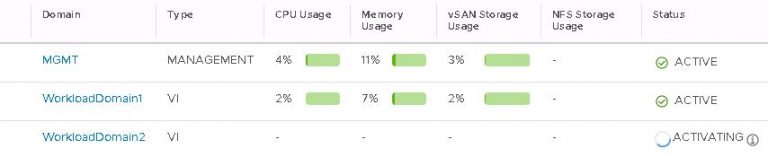
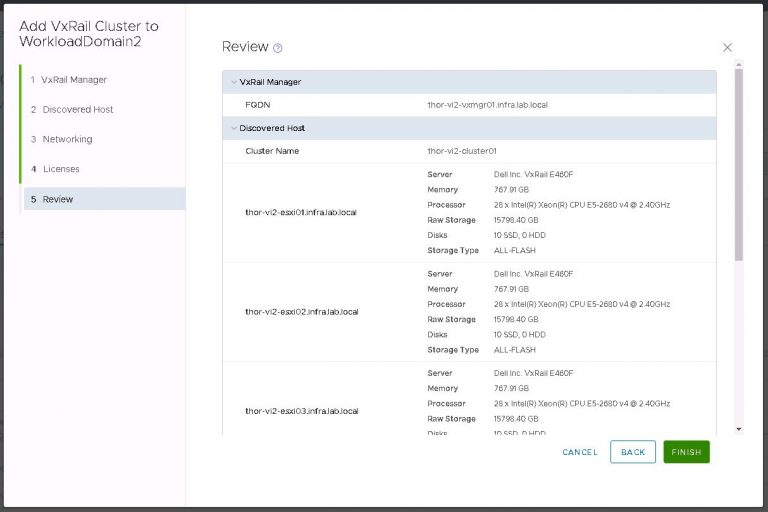 I monitored the progress in the SDDC manager tasks view. It took about 40 minutes to run the cluster addition tasks and display my new VI workload domain in SDDC manager.
I monitored the progress in the SDDC manager tasks view. It took about 40 minutes to run the cluster addition tasks and display my new VI workload domain in SDDC manager.