I make no bones about being a reformed server hugger. One of my more recent catchphrases is “I’d be a happy man if I never had to build another physical server spec”. So for those currently in the VMware ecosystem, I’ve been turning a lot of attention toward VMware Cloud on various hyperscalers. There is a particular emphasis on AWS and Azure here. GCP is also available, I just don’t get asked about it a lot. Sorry Google.
Some of the most frequent questions I hear include topics such as difficulty to setup and maintain the platform, required knowledge of the underlying hyperscaler, the ubiquitous horror of “vendor lock-in”, and of course the overall cost of the solution. The latter is a whole series of articles in itself, so I’ll be tactically dodging that one here. The short answer, as it so often is, is “it depends”.
Another frequently asked question surrounds the whole idea of “why should I be in the cloud”. There are quite a few well documented use cases for VMware Cloud. The usual ones like disaster recovery, virtual desktop, datacenter extension or even full on cloud migration. One that’s sometimes overlooked is that because SDDCs are so quick to spin up and can be done so with on-demand pricing, they’re great for short lived test environments. Usually, you can create an SDDC, get connectivity to it and be in a position to migrate VMs from your on-premises cluster or DR solution within a couple of hours. No servers to rack, no software to install, no network ports to configure, no week long change control process to trundle through.
For those organisations currently using native cloud services, there are a whole load of additional use cases. Interaction with cloud native services, big data, AI/ML, containers, and many many more buzzwords.
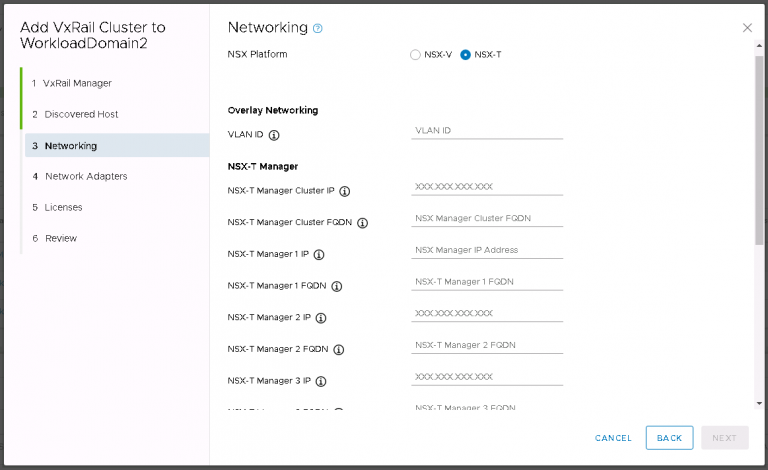
What I can do is show you how quickly you can get a VMC on AWS SDDC spun up and ready for use. The process is largely the same for Azure VMware Solution, with the notable difference that the majority of the VMC interaction in Azure is done via the Azure console itself. The video below gives you an idea of what to expect when you get access to the VMC console and what creating a new SDDC on AWS looks like.
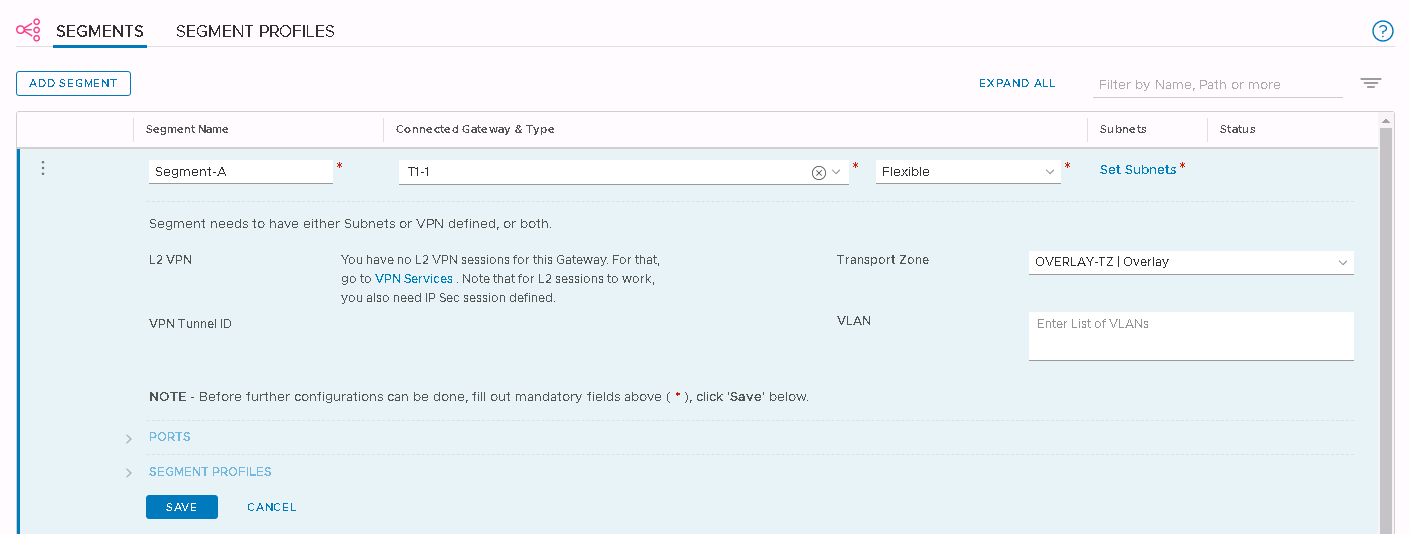
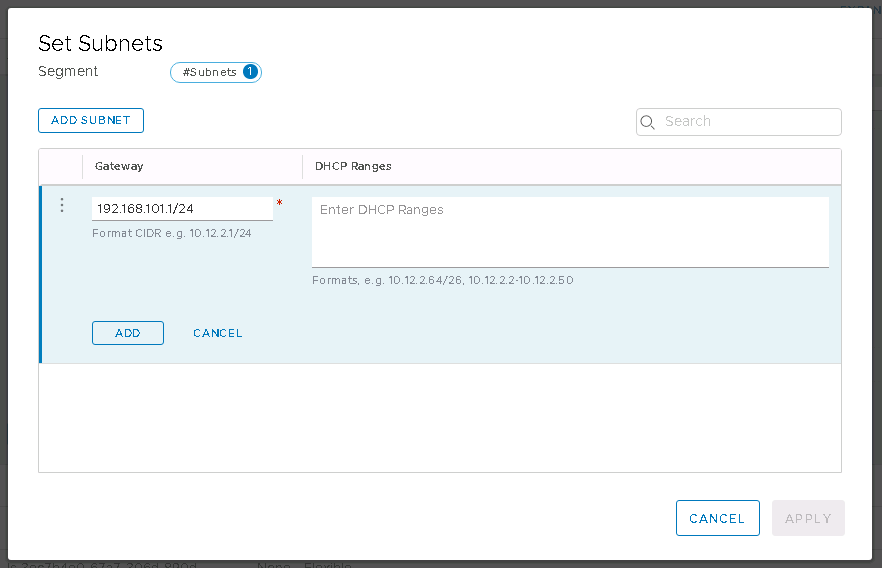
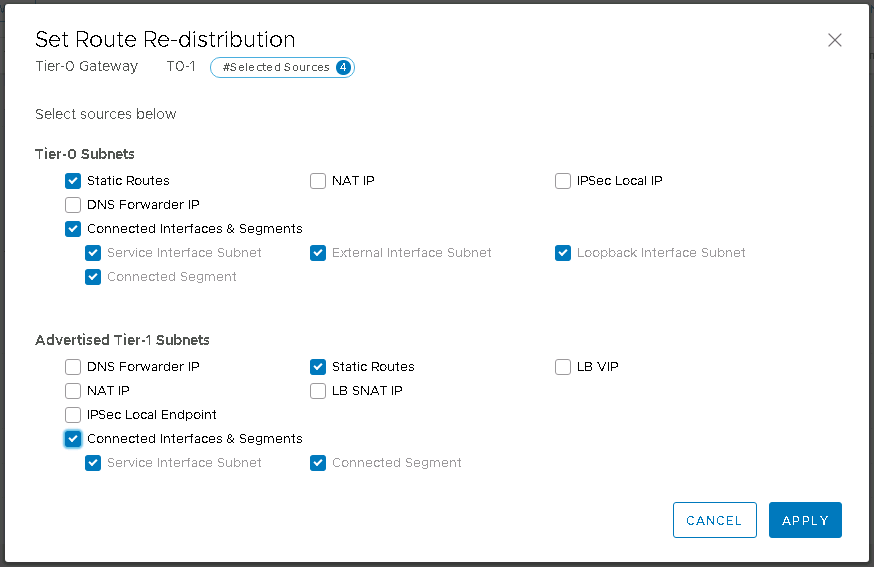
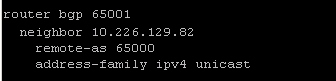
I’ve included some detail on setting up a route based VPN tunnel back to an on-premises device. Policy based and layer 2 VPN are also available, but as my device (a Ubiquiti Edgerouter) is BGP capable I’m taking what I consider to be the easy option. I prefer to use a route based VPN because it makes adding new networks easier and allows a great deal of control using all the usual BGP goodness any network team will be comfortable with. There is also some content covered for firewall rules, because as you might expect they are a core component of controlling access to your newly created SDDC.
Something you may immediately notice (although not explicitly demonstrated in the video) is that the only interaction I had with AWS native services throughout the SDDC creation was to link an existing AWS account to the SDDC. For those without AWS knowledge, this is an incredibly straightforward process with every step walked through in just enough detail. If you’re creating an SDDC, you need to link it to an AWS account. If you don’t already have an AWS account, it’ll take less than five minutes to create one.
The only other requirement right now is to know a little bit about your network topology. Depending on how complex you want to get with VMC on AWS in the future, you’ll need to know what your current AWS and/or on-premises networks look like so you can define a strategy for IP addressing. But of course even if you never plan on connecting the SDDC to anything, you should still have an IP addressing strategy so it doesn’t all go horribly wrong in the future when you need to connect two things you had no plan to connect when you built them.
The one exception I’ll call out for the above is self-contained test environments. What I’m thinking here is a small SDDC hosting some VMs to be tested and potentially linked to an AWS VPC which hosts testing tools, jumpboxes, etc on EC2. If this never touches the production network, fill your boots with all the overlapping IP addresses you could possibly ever need. In this case, creating an environment as close as possible to production is critical to get accurate test results. Naturally, there’s also a pretty decent argument to be made here for lifecycling these type of environments with your infrastructure as code tool of choice.
On that subject, how do you connect a newly created SDDC to an AWS VPC?
This is the process at it’s most basic. Connecting a single VMC SDDC to a single AWS VPC in a linked AWS account. Great for the scenario above where you have self-contained test environments. Not so good if you have multiple production SDDCs in one or more AWS region and several AWS accounts you want them to talk to. For that, we’ve got SDDC groups and transit gateways. That’s where the networking gets a little fancier and we’ll cover that in the next post.
I hope by now I’ve shown that a VMC on AWS SDDC is relatively easy to create and with a bit of help from your network team or ISP, very easy to connect to and start actively using. I’ve tried to keep connectivity pretty basic so far with VPN. If you are already in the AWS ecosystem and are using one or more direct connect links, VMC ties in nicely with that too.
The concept of vendor lock-in comes up more than once here. It’s also something that’s come up repeatedly since Broadcom appeared on the VMware scene. To what extent do you consider yourself locked-in to using VMware and more importantly, what are the alternatives and would you feel any less locked-in to those if you had to do a full lift & shift to a new platform? If you went through the long and expensive process to go cloud native, would going multi-cloud solve your lock-in anxiety? Are all these questions making you break out in a cold sweat?
If you take nothing else away from all the above, I hope you’ve seen that despite some minor hyperscaler platform differences, VMware Cloud is the same VMware platform you’re using on-premises so there is no cloud learning curve for your VMware administrators. You can connect it to your on-premises clusters and use it seamlessly as an extension of your existing infrastructure. You can spin it up on demand and scale up and down hosts quickly if you need disaster recovery. You can test sensitive production apps and environments in isolation.
As I brought up those ‘minor hyperscaler differences’, how would they impact your choice to go with VMC on AWS, Azure VMware Solution, GCP, or another provider? As the VMware product is largely the same on any of the above, it comes down to what relationship you currently have (if any) with the cloud provider. The various providers will have different VMC server specs and connectivity options which would need to be properly accounted for depending on what your use case is for VMC. This is another instance of it being a whole topic by itself. If you’re curious, the comment box is below for your questions.
In the next post on this subject I’ll go into more detail about some complex networking and bring in the concept of SDDC groups, transit connect and AWS transit gateways. I’ll also cover a full end-to-end HCX demo in the next post, so you’ll have what is possibly the best way (in my biased opinion anyway) of getting your VMs into VMware Cloud on AWS.